|
I am currently a Research Engineer at Tencent (WeChat). I received my Master's degree from Institute of Computing Technology, Chinese Academy of Sciences, and Bachelor's degree in Computer Science from Northwestern Polytechnical University. I'm interested in computer vision, machine learning, and embodied AI. Recently, my research focuses on Video Generation (Diffusion Models, RGBA), Multimodal LLMs, 3D Human Motion Capture & Generation, and Embodied AI. |

|
|
|
|
|
|

|
Yiheng Li*, Zhuo Li* (Project leader), Ruibing Hou, Yingjie Chen, Hong Chang, Hao Liu, Shiguang Shan Under review at NeurIPS, 2026 HF Paper / arXiv We introduce OmniHuMo, a large-scale multimodal motion dataset, and AnyMo, a unified framework combining a Residual FSQ-based motion tokenizer with a scalable masked modeling transformer for any-modality conditional motion generation. Deployed in WeChat multimodal generation business. |
|
|
|

|
Zhuo Li*, Mingshuang Luo*, Ruibing Hou , Xin Zhao , Hao Liu , Hong Chang, Zimo Liu, Chen Li ICCV, 2025 Project Page / Code / arXiv In this paper, we propose Morph, a Motion-free physics optimization framework, comprising a Motion Generator and a Motion Physics Refinement module, for enhancing physical plausibility without relying on costly real-world motion data. |

|
Zhelun Shen*, Zhuo Li*, Chenming Wu, Zhibo Rao, Lina Liu, Yuchao Dai, Liangjun Zhang Pattern Recognition, 2025 Code / arXiv / Video We propose CMD, addressing the multimodal disparity distributions caused by smooth L1 loss and soft argmin in unsupervised domain adaptation. We introduce uncertainty-regularized minimization and anisotropic soft argmin to encourage unimodal predictions in target domains. The method won the Championship in Argoverse Stereo Competition (CVPR 2021). |
|
|
|
|
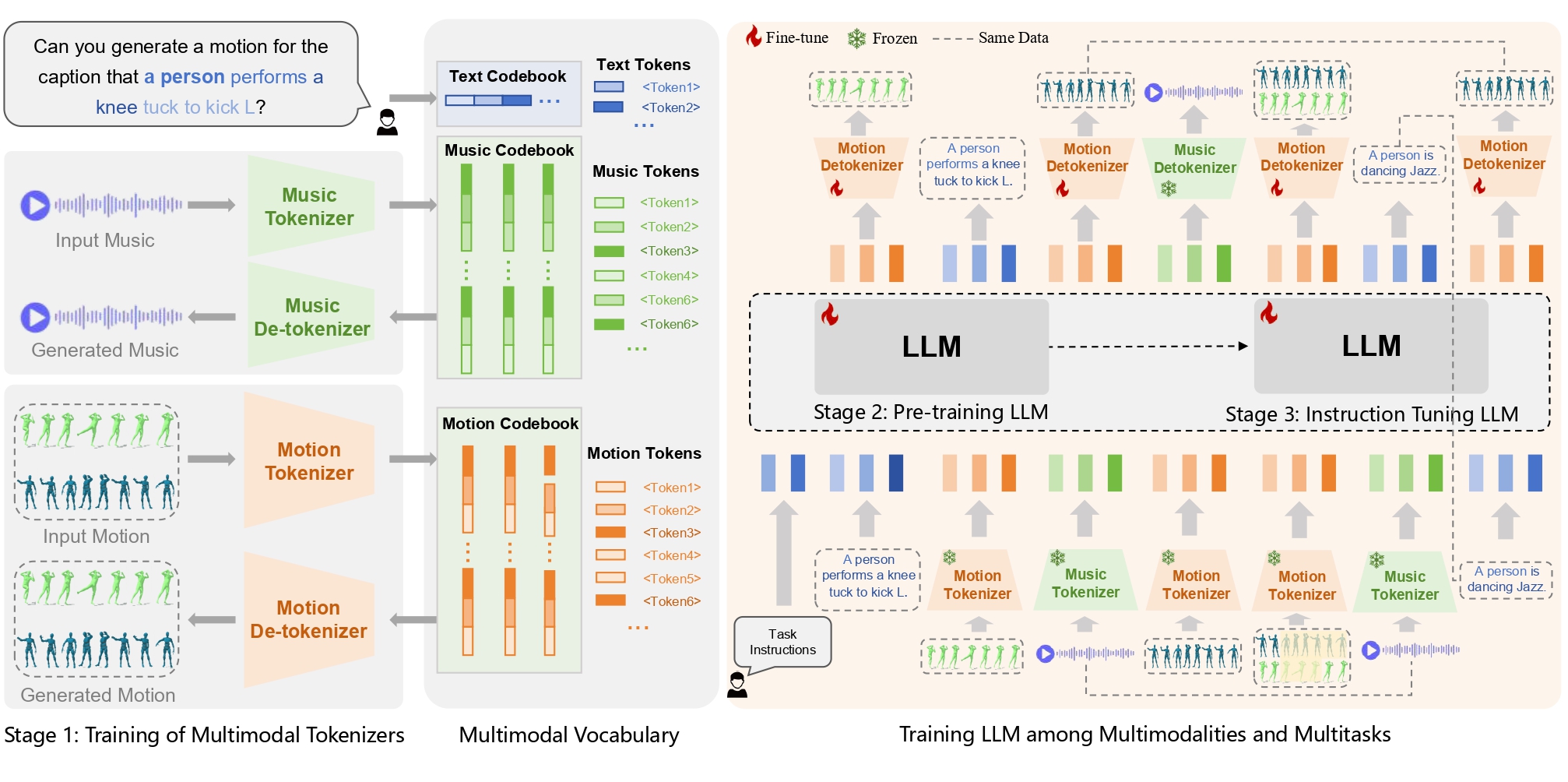
Mingshuang Luo, Ruibing Hou , Zhuo Li, Hong Chang, Zimo Liu, Yaowei Wang, Shiguang Shan NeurIPS, 2024 arXiv M³GPT — an advanced Multimodal, Multitask framework for Motion comprehension and generation. It utilizes an Autoregressive architecture to build a unified representation space for motion and music. |
|
|
|
|
Jiajun Song* , Zhuo Li* , Weiqing Min, Shuqiang Jiang ToMM, 2023 arXiv The method was used in Meituan for food image retrieval. |
|
|
|
|
Zhuo Li, Weiqing Min, Jiajun Song, Yaohui Zhu, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang AAAI, 2022 Code / arXiv PNP Loss — a simple, effective and generalization-friendly loss function for image retrieval. The method was used in Meituan app for food image retrieval. |
|
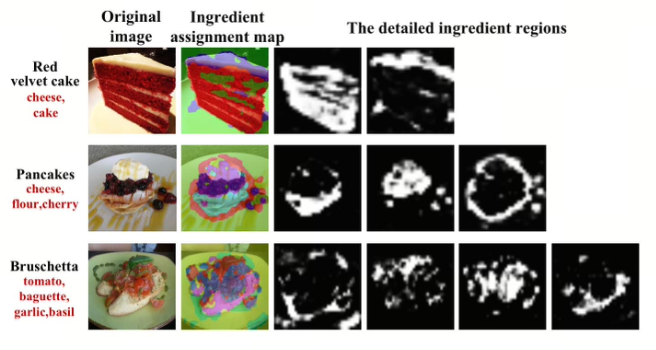
Zhiling Wang, Weiqing Min, Zhuo Li, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang IEEE Transactions on Image Processing (TIP), 2022 arXiv An ingredient-oriented multi-task framework that learns an ingredient dictionary for visual region discovery and builds a semantic-visual graph (GCN) for ingredient relationship modeling, jointly improving food recognition and ingredient prediction. Deployed in Meituan's "Scan to Discover" business. |
|
|
Jiajun Song, Weiqing Min, Yuxin Liu, Zhuo Li, Shuqiang Jiang, Yong Rui MIPR, 2022 Code NoLoTransformer — a Transformer-based metric-learning framework for fine-grained food image retrieval. It introduces a Patch Attention Module (PAM) that adaptively reweights noisy patches (e.g., plates, side dishes) and a Local Perception Unit (LPU) that injects convolutional locality to capture fine-grained ingredient cues, achieving SOTA on three food retrieval benchmarks. |
|
|
|

|
Website LargeFineFoodAI — a workshop of large-scale fine-grained food analysis on ICCV 2021, including invited talks, presentation from accepted papers and a competition on large-scale food image recognition and retrieval. |
|
|
|
|
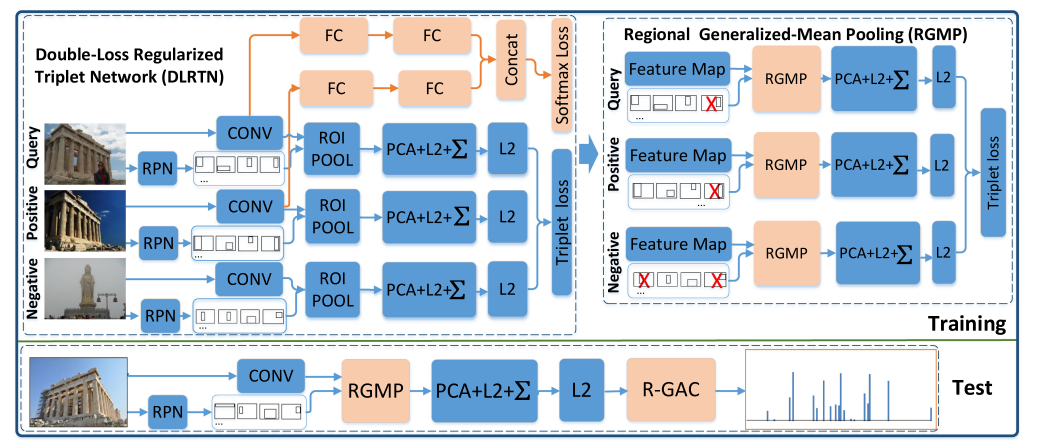
Weiqing Min, Shuhuan Mei, Zhuo Li, Shuqiang Jiang TMM, 2020 arXiv |
Template adapted from this awesome page.